
Introduction
After learning a bit about classes, objects, and access modifiers, we can move on to another important concept of Constructors and Destructors. This part will cover Constructors. We'll explore what are constructors, why we need them, types of constructors, and their semantics in C++ as usual.
So without wasting any time, let's get started.
What is a constructor
A constructor is a method just like another method in a class, but it has a special name for a reason. The name itself speaks,
Constructor
, which will get called just after the object gets created. A constructor is just a method but it should only have the name same as of the class, that's the thing that distinguishes it from other methods.
The main thing that stands out for a constructor is that you don't have to call it. It gets called automatically (just magically), yes you don't have to call it explicitly. That's a great feature in Object-Oriented Programming. We can control the flow of the program according to our needs.
A constructor has certain features or principle that makes it different from the rest of the class methods:
- There is no return type for a constructor.
- The name of the constructor should be the same as the class name.
- There can be multiple constructors for a class (depending on the parameters passed to it).
- A constructor gets called automatically when an object is instantiated (created).
Why do we need a constructor?
Let's suppose you wanted to initialize some variables (properties) before the main loop of a program starts or initiates. This can be done manually by accessing them in the mail function but for many objects, this can get really boring to write every time. This is where the constructor comes in and just improves the overflow structure and manageability of the program.
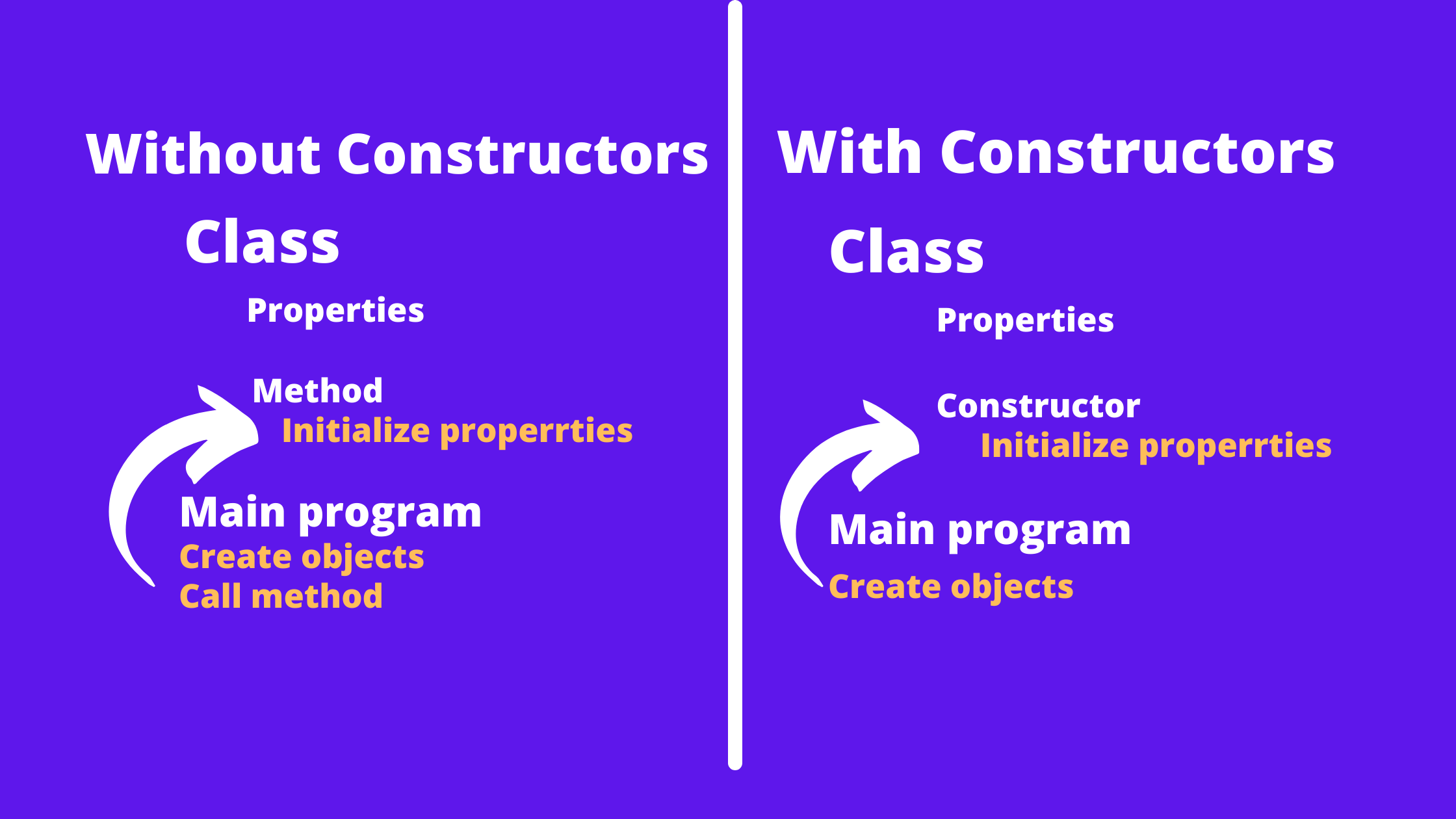
This looks silly but is actually used a lot just beyond initialization, you might want certain things to be done as soon as the object gets created. All ideas and flow of the program in a particular desired manner are all possible due to constructors. It is also a way of automating several repetitive tasks for better design and maintaining the codebase.
Define a constructor for a class in C++
Now, it's time to get into code, and let's see how to define a constructor in a class using C++.
#include "iostream"
using namespace std;
class blog
{
public:
// defining a constructor for the blog class
blog()
{
cout<<"Call from constructor\n";
}
};
int main(){
blog post1;
return 0;
}
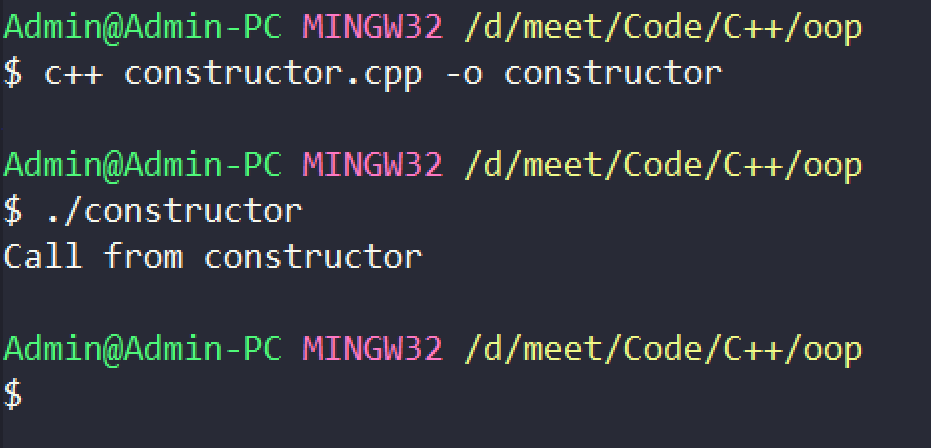 This is how you define a class in C++. A constructor doesn't even have a return type of void, literally, it doesn't return anything. A Constructor can do anything another normal method can do except to return anything. We can also pass certain parameters to it as well.
This is how you define a class in C++. A constructor doesn't even have a return type of void, literally, it doesn't return anything. A Constructor can do anything another normal method can do except to return anything. We can also pass certain parameters to it as well.
The thing here is that, the constructor should be public if you want to call it from the main function or anywhere else outside the class(class itself / friend class / derived class). You can make it private or protected as per your needs and the hierarchy of your application. If you want to know more about those access modifiers(public/private/protected), you can check the previous part of this series.
Remember, you cannot call the constructor from the main function if it is not public.
We can actually create some good examples where the constructor plays a vital role in the design and the feasibility of the actual idea.
Let's say we want to create three objects, each taking the same input of properties from the user but the value will be different as obvious and also determine another property based on an input. Should we write those inputs for every object or write a function for the same. The latter will be the best choice, but which function are you thinking of? If that's a constructor then you are correct! Ya we can even write a normal method but we have a print function called up already, that might create some undesired behavior like unreferenced variables and segmentation fault while dealing with complex data structures or large applications.
#include "iostream"
#include "string"
using namespace std;
class Animal
{
public:
int legs;
string name;
string type;
Animal()
{
cout<<"Who is the Animal? ";
cin>>type;
cout<<"Enter the name of Animal? ";
cin>>name;
cout<<endl;
if(type.compare("dog")==0)
legs=4;
else if(type.compare("monkey")==0)
legs=2;
else
legs=0;
}
void print()
{
if(legs==0)
cout<<type<<"'s name is "<<name<<endl;
else
cout<<name<<" has "<<legs<<" legs.\n";
cout<<endl;
}
};
int main(){
Animal obj1,obj2,obj3;
obj1.print();
obj2.print();
obj3.print();
return 0;
}
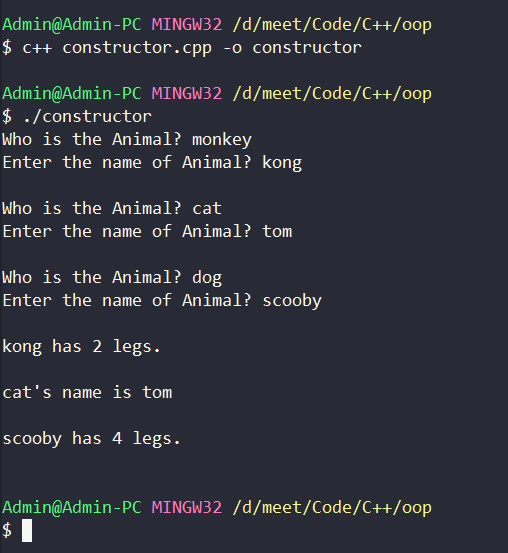
We can see how well this can scale for creating many objects. This is just one of the examples where the constructor just single-handedly takes care of many things. We can always create an array of objects but to keep things simple here, we have hardcoded the object names.
Types of Constructors
Well, won't it be nice to pass the values to the constructor and then do certain computations? There is a solution to that, we can overload functions i.e we can create multiple constructors each having a unique combination of parameters associated with it.
The following are the types of constructors:
- Default Constructors
- Copy Constructors
- Parameterized Constructor
Default Constructor
This is the constructor which we have used so far, even if we don't define a constructor, the C++ compiler automatically creates one which does nothing.
We have already seen the normal constructors without any parameters, just a simple function that does some I/O to the console.
Copy Constructor
This is a great feature of constructors, you can copy certain properties of previously created objects or define new ones and pass them to the constructor. This is why I said we can have multiple constructors depending on the number of parameters or the type of parameters passes to it.
So, with that said, we can basically define constructors for different purposes with different requirements and conditions. This just opens up a new dimension of creating complex functions and programs with great flexibility and adaptivity.
#include "iostream"
#include "string"
using namespace std;
class Animal
{
public:
int legs;
string name;
string type;
Animal()
{
cout<<"Who is the Animal? ";
cin>>type;
cout<<"Enter the name of Animal? ";
cin>>name;
cout<<endl;
if(type.compare("dog")==0)
legs=4;
else if(type.compare("monkey")==0)
legs=2;
else
legs=0;
}
// copy constructor with reference of an object of the same class
Animal(Animal &obj)
{
cout<<"This is my pet "<<obj.type<<", "<<obj.name<<endl;
}
void print()
{
if(legs==0)
cout<<type<<"'s name is "<<name<<endl;
else
cout<<name<<" has "<<legs<<" legs.\n";
cout<<endl;
}
};
int main(){
Animal obj1;
Animal obj4(obj1);
obj1.print();
return 0;
}
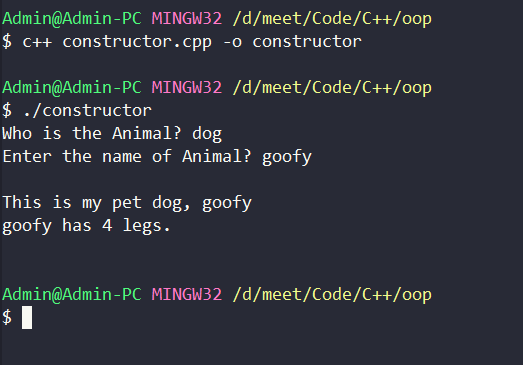
In the above example, we have defined another constructor that accepts a parameter that is a reference to another created object and basically does some I/O operations.
Why would we need this?
Well, the name itself says it all.
To copy the values of existing objects
with slight or minor modifications. It basically depends on how you want to copy the object into another. This can also be applied to additional class properties and just change the copy constructor and there it is, big tasks performed with minimal changes. We can also be used to modify the existing objects (though it can get a security issue, still pretty cool) by accessing the properties of that object in the copy constructor.
Parameterized Constructor
Now, we know that we can pass parameters to our constructors, let's exploit that functionality to create all sorts of constructors. No, I'm just kidding, you can create multiple constructors by passing in various combinations of parameters to it.
Let's take an example, instead of taking input from the default constructor we can pass in the values while creating the object, and the constructor which matches the parameters gets called.
#include "iostream"
#include "string"
using namespace std;
class Animal
{
public:
int legs;
string name;
string type;
// default constructor
Animal()
{
cout<<"Who is the Animal? ";
cin>>type;
cout<<"Enter the name of Animal? ";
cin>>name;
cout<<endl;
if(type.compare("dog")==0)
legs=4;
else if(type.compare("monkey")==0)
legs=2;
else
legs=0;
}
// constructor with two parameters (both String)
Animal(string type, string name)
{
cout<<"This is my pet "<<type<<", "<<name<<endl;
}
// constructor with one parameter(String)
Animal(string name)
{
cout<<"Hello, "<<name<<endl;
}
void print()
{
if(legs==0)
cout<<type<<"'s name is "<<name<<endl;
else
cout<<name<<" has "<<legs<<" legs.\n";
cout<<endl;
}
};
int main(){
Animal obj1;
Animal obj2("dog", "scooby");
Animal obj3("Pomello");
obj1.print();
return 0;
}
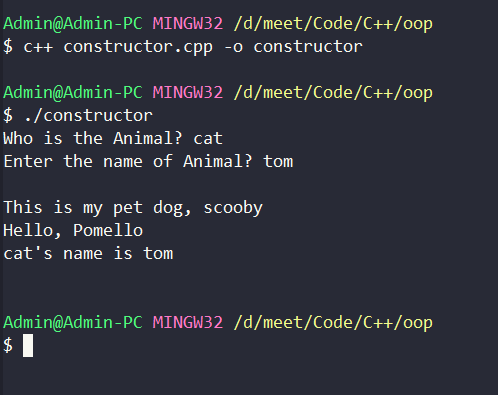
We created the first object without any specification but the second object was passed with two parameters and we indeed called the correct constructor. The third object was just given a single parameter and again called the required constructor.
So, we can see that a particular constructor is called which matches the parameters passed to it. That's quite an intelligent and smart design. This just improves the overall diversity and adaptability hand in hand.
Function/Constructor Overloading
When a single function(same name) has different implementations depending on the parameters passed to it is called Function overloading.
The thing above i.e Parameterized Constructors is technically called Function Overloading (Constructor in this case). We will look into this topic in much detail when we cover more on methods. But this might be enough to get your head around the concept of overloading in OOP.
Let's say we have a function that takes two parameters by default but also can take three parameters when given. We can process them by having a different implementation. This creates a lot of freedom and broadens the scope of customization in complex applications.
#include "iostream"
using namespace std;
void intro(string name, int age)
{
cout<<name<<" is "<<age<<" years old.\n";
}
void intro(string name)
{
cout<<"Hello, "<<name<<endl;
}
int main(){
intro("Ash",10);
intro("Brock");
return 0;
}
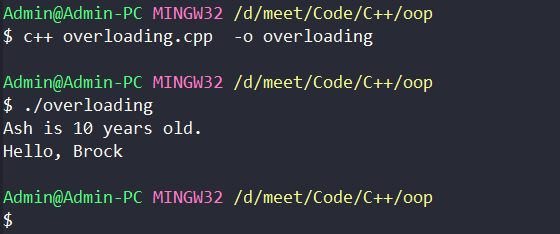
In this example, we have a single function
intro
but it has two implementations, one has a two-parameter and the other has just one. This is called Function Overloading. We just applied this in the functions in classes called constructors but the concept is the same. We'll dive into Overloading in the next few sections.
Conclusion
That is it from this part. We'll see
Destructors
in the next one. From this part, we learnt about constructors and how important they are in creating the desired flow to our application. We also touched on the types of constructors and function overloading a bit, which are also important aspects of OOP. That's it from this one.
Happy Coding :)